
욤미의 개발일지
[논문 리뷰] Instruction Tuning with GPT-4 본문
Baolin Peng∗ , Chunyuan Li∗ , Pengcheng He∗ , Michel Galley, Jianfeng Gao Microsoft Research
{bapeng,chunyl,penhe,mgalley,jfgao}@microsoft.com
2023.4
66회 인용
- GPT-4 모델을 활용하여 Self-Instruct로 데이터셋을 생성
- 생성한 데이터셋을 활용하여 LLaMA를 Instruction Tuning
Background
GPT model Training

본 논문에서는 Fine-tuning에 해당하는 Instruction Tuning을 핵심으로 다루고 있으며 RLHF 에 해당하는 Reward모델도 사용하고 있다.
Instruction Tuning
- pre-train된 모델에 prompt-completion 쌍의 데이터로 supervised learning을 수행하는 것
- 즉, 다양한 NLP 작업들을 명령을 통해 수행하도록 모델을 학습시키는 방법
한계점1. LLM과 human written instruction data에 의존
- Human written instruction data의 경우
- 생성 시 많은 비용 발생
- 인간이 직접 생성하므로 다양성과 창의성 부족
→ 본 논문에서는 self-instruct방법으로 이를 해결하고자 함
한계점2. Hallucination
- 대답으로 사실이 아닌 것을 그럴듯하게 생성하는 것
- 오류가 있는 데이터를 학습했거나, 학습 데이터가 부족할 때 발생
- 사실과 오류가 섞여 오답을 알아차리기 어렵다.

Self-Instruct
- Pre-trained language model의 생성 결과를 반복적으로 활용하여 스스로 Instruction following capability를 향상시키는 프레임워크
- Instance를 생성 → 필터링 과정을 통해 Instruction following 데이터를 구성
- 생성한 Instruction으로 pre-trained model을 fine-tuning
- annotation-free method: 첫 seed 구성 외에는 과정에서는 annotation이 사용되지 않음

Reinforcement learning with human feedback(RLHF)
- 강화학습을 이용하여 PLM의 output을 human이 원하는 방식에 가까워지도록 학습하는 과정 = 인간 피드백을 통한 강화학습
- Reward model의 동작
- LM으로 하나의 쿼리에 대해 k개의 response 생성
- Human scoring 과정: 사람이 k개의 response를 랭킹
- Human score를 바탕으로 Reward model을 학습

GPT-4 (OpenAI, 2023.03)
GPT-4 is a large multimodal model (accepting image and text inputs, emitting text outputs) that, exhibits human-level performance on various professional and academic benchmarks.
- GPT-3(175B, 2020): In context Learning 활용, fine-tuning없이 prompt만으로 task 수행
- ChatGPT(2022): GPT-3.5 (GPT-3 + RLHF)
- GPT-4(2023): ChatGPT + 멀티모달 (코드, 텍스트에 더해 이미지 분석이 가능해짐)
- 많은 글자수 추론이 가능해짐: 시, 소설 생성도 가능
- 많은 글자수 추론이 가능해짐: 시, 소설 생성도 가능
Method
Instruction-following Data
- Language Model을 활용해 데이터를 생성하고 이를 LLM을 학습하는 연구가 진행 중
- 모델로 생성한 데이터를 사용해 학습할 때 장점
- Zero-shot capability 향상
- Human-written instruction의 불필요
- GPT-4를 사용하여 Instruction data 생성
- 생성한 데이터로 3가지 다른 모델을 Instruction Tuning
- 모델 및 평가 (Human evaluation, Automatic evaluation, Rouge-L Score)

본 연구에서 GPT-4로 생성한 데이터
Self-Instruct (Wang et al., 2022) 방식을 활용해 GPT-4로 Instruction-following data 생성
1. English Instruction-Following Data
- Alpaca instruction (52K)
- English GPT-4 responses

2. Chinese Instruction-Following Data
- Translated Alpaca instruction (52K) using ChatGPT
- Chinese GPT-4 responses

3. Comparison Data
- 생성한 데이터로 세가지 모델을 Instruction Tuning을 시킴
- 모델이 생성한 response에 대해 GPT-4가 1~10 점으로 scoring
- source: 모델
- score: response에 대한 점수

4. Answers on Unnatural Instructions
- Unnatural data의 instructions (9K)
- GPT-4가 생성한 response

Instruction Tuning on LLM
생성한 2가지 언어(영어, 중국어)의 Instruction-following data로 LLaMA를 Instruction Tuning

Reward Models
- RLHF의 핵심 부분으로 prompt와 response에 대한 scalar reward를 예측
- 사람의 선호도를 직접적으로 반영
- 학습하기 위한 Large-scale comparison data 필요 → high cost
- 반면 GPT-4는
- 스스로 오류 판별과 보완, 답변의 품질 판단 가능 → 따라서 본 논문에서는 GPT-4를 활용하여 comparison data 생성
- Reward Model: OPT 1.3B모델 사용
- Comparison data
- 1 prompt - k response로 구성
- 각 response 별로 1~10점 s 로 구성
- Object: reward model이 정답에 더 확신을 갖는 방향으로 학습
Experiments

Dataset
- 71개 user-oriented application을 바탕으로 manual하게 생성한 데이터 (252개)
- Human evaluation에서 사용
- 8가지 카테고리에 대한 어려운 질문 (80개)
- Automatic evaluation에서 사용
- Instruct GPT로 생성한 unnatural instructions-input-output 데이터 (68K)
- ROUGE-L score evaluation에서 사용
Experiments: Human Evaluation
- HHH Alignment criteria: AI 시스템과 human value사이의 alignment 평가 지표
- 3가지 평가요소
- Helpfulness: AI가 instruction에 정확하게 응답하여 human의 목표를 달성하는가
- Honesty: AI가 사실만 응답하며, 사실 여부가 확실하지 않은 경우 이를 고지하는가
- Harmlessness: 혐오 발언 혹은 폭력 조장 등 인간에게 해가 되지는 않는가
- 각 Instruction과 Response를 비교
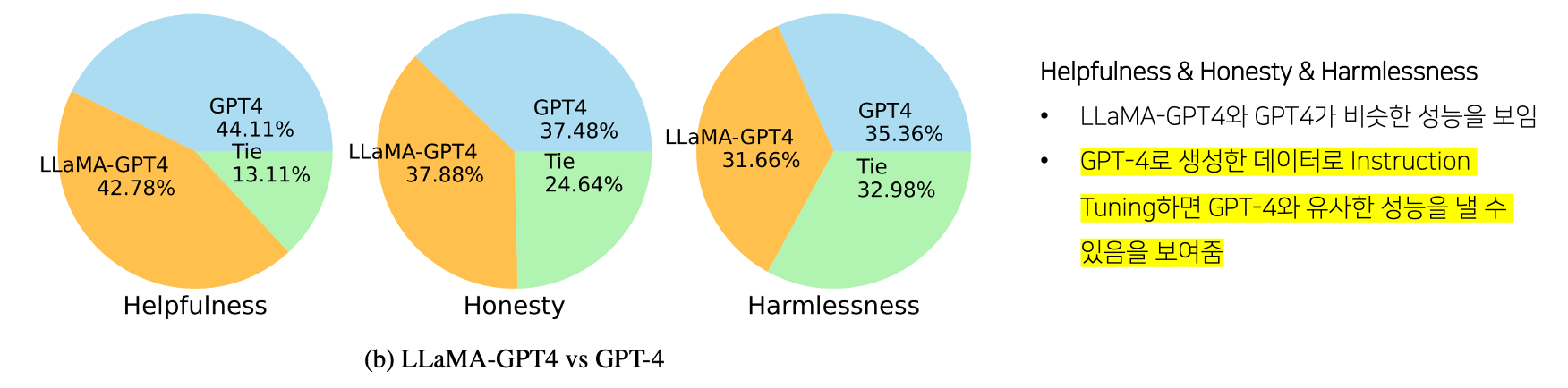
1. LLaMA-GPT4 & LLaMA-GPT3
- LLaMA-GPT4: GPT4로 생성한 Instruction-following data로 LLaMa를 Instruction Tuning
- LLaMA-GPT3: GPT3로 생성한 Instruction-following data로 LLaMa를 Instruction Tuning (=Alpaca 모델과 동일)

2. LLaMA-GPT4 & GPT4
- LLaMA-GPT4: GPT4로 생성한 Instruction-following data로 LLaMa를 Instruction Tuning
- GPT4: 기본 GPT4
Experiments: Automatic Evaluation
- GPT4활용 response에 대해 1~10 scoring
- Vicuna-Instruction-80 data 활용
- 80개 질문 → 총점 범위 80~800점
- Reward 모델 LLaMA-GPT4에 대해 각각 effectiveness를 평가
- ChatGPT, GPT4를 비교 모델로 사용
Effectiveness of Reward models
- 1 Question - 1 Response → baseline B로 표기
- 1 Question - 5 ranked Response → 숫자로 표기
- 한개의 질문에 대해 5개의 응답을 생성
- 각 응답에 대해 reward model을 활용해 ranking
- 각 질문 별 response들을 rank별로 group 1-5 구성

Effectiveness of LLaMA-GPT4
본 논문에서 생성한 Instruction following data는 영어와 중국어 2가지 → 따로 비교
1. English Dataset
- 모델: LlaMA-GPT4, GPT4, ChatGPT, Bard, Vicuna, Alpaca, LLaMA (총7개)
- 비교 모델: ChatGPT, GPT-4

2. Chinese Dataset
- 모델: LlaMA-GPT4, GPT4, ChatGPT, Bard, Vicuna, Alpaca, LLaMA (총7개)
- 비교 모델: GPT-4
- Question 혹은 Response를 ChatGPT를 통해 중국어로 translated
- Generated: 질문을 영어에서 중국어로 번역 → 중국어로 번역한 질문 입력 → 중국어 응답 도출
- Translated: 영어로 된 질문 입력 → 영어 응답 도출 → 응답을 중국어로 번역
- (a) Translated : Translated
- (b) Translated : Generated
- (c) Generated : Translated

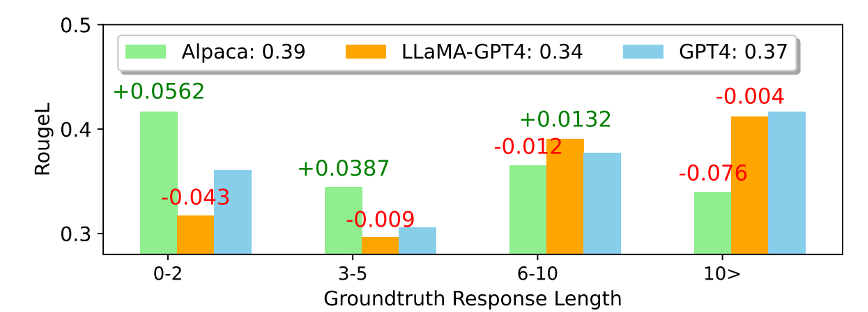
Experiments: ROUGE-L score evaluation
- Unnatural Instructions (Honovich et al., 2022)
- 데이터의 Ground Truth response의 길이 기준 → 4개 그룹
- 각 그룹별 ROUGE-L 점수의 평균으로 plotting
- +, - 표시: GPT4와의 차이 표시

Conclusion
- 본 논문은 GPT4가 스스로 응답에 대한 품질 판단 가능하다는 점과 기존에 연구 되었던 Self-Instruct 방법의 우수성을 바탕으로 연구를 진행하였다.
- 작은 모델에 GPT4로 생성한 데이터로 Instruction tuning을 시키면 GPT4에 근접한 성능으로 향상시킬 수 있다는 것을 시사했다.
- 4가지 데이터와 instruct-tuned 모델을 공개하고 있다.
- LLaMA 7B 모델보다 큰 모델을 활용한 다면 더욱 높은 성능 향상을 볼 수 있을 것으로 기대한다.



